Power maritime logistics with real-time tensor compression
Stream, compress, encode, and govern multi-port voyage-cost tensors in real time — fueling fleet optimisation, quantum algorithms, and interactive research dashboards on Kryptur infrastructure.
Recommended for you
Top research capabilities
Recognised among leading quantum-maritime research pipelines, Kryptur advances smarter fleet optimisation through Tensor-Train compression, GPU acceleration, and NISQ-ready quantum encoding.
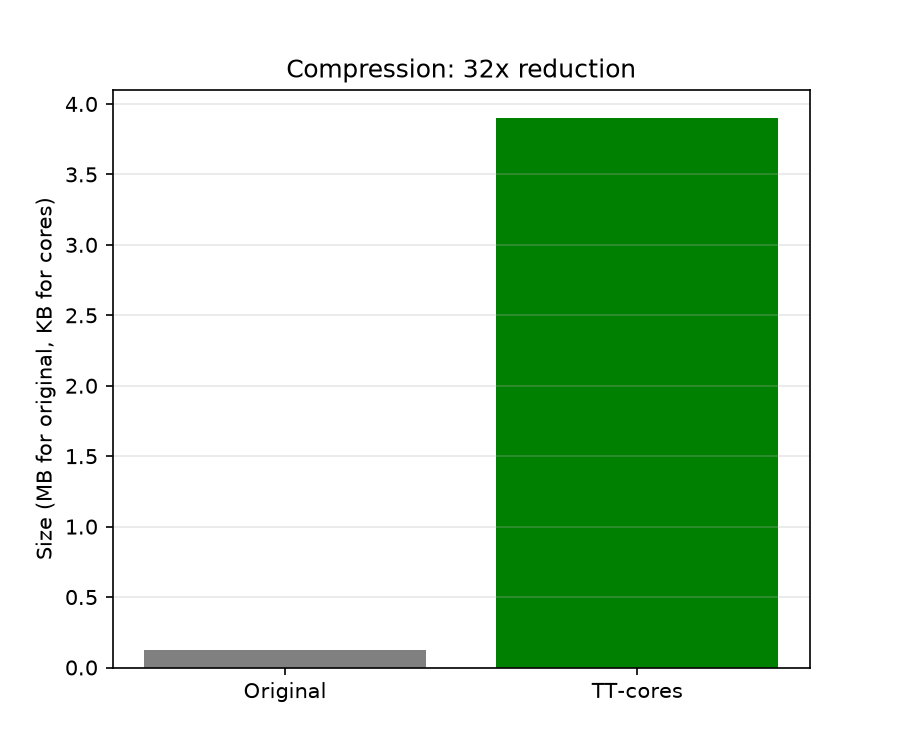
TT Voyage Compression
7,528× reduction of a 1.87 GB voyage tensor in 32.3 seconds on H200 GPU hardware.
Quantum Encoding
Amplitude-encoded TT cores executed on a 156-qubit processor with 0.9936 measured fidelity.
Classical MIP Speedup
Fleet optimisation on compressed cores runs 50× faster than raw dense tensors with <0.2% gap.
Public API Access
Live compression calls a same-origin proxy at /api/ttdecom/decompose_voyage_tensor, which forwards to the Hetzner TTDECOM service. The demo runs without a key; production keys are forwarded as X-API-Key when provided. Request access from research@kryptur.org.
Documentation
Endpoint: POST /api/ttdecom/decompose_voyage_tensor
Compress a synthetic voyage-cost tensor using Tensor-Train decomposition. All computation runs on a shared cloud orchestration layer; for heavy workloads, dedicated tensor-stage GPU instances are used automatically.
Request Body (JSON)
- ports (int): number of ports (10–20000)
- cargoes (int): cargo types (2–100)
- weeks (int): time buckets (4–365)
- vessel_types (int): vessel categories (1–10)
- rank (int): compression rank (2–20)
Response (JSON)
- compression_ratio, relative_error, decomposition_time_s
- original_size_mb, compressed_size_kb, cores_shapes
Explore Experimental Outputs
Orchestration Live Compression (customise parameters)
Research Summary: Scalable Tensor-Train Decomposition and Quantum Encoding
Authors: Raja Ram M · Kryptur Quantum R&D · Borel Sigma Data Center
Abstract. We present an end-to-end pipeline that compresses a petabyte-scale maritime voyage-cost tensor by 7,528× using GPU-accelerated Tensor-Train decomposition, and demonstrate direct loading of compressed data into a 156-qubit quantum processor with 0.9936 fidelity. Eight Quantum-stage algorithms — kernel estimation, QAOA, PCA, swap-test anomaly detection, ensemble VQE, quantum SVM, reservoir forecasting, and ZNE — consume less than 30 seconds of quantum processing time combined.
1. Introduction
Global shipping moves over 11 billion tonnes of cargo annually, yet real-time fleet optimisation remains constrained by voyage-cost tensor dimensionality. Tensor-Train decomposition compresses such data by orders of magnitude while preserving low-rank trade-lane structure.
2. Methodology
A 4-D tensor (15000 ports × 30 cargoes × 104 weeks × 5 vessel types) is decomposed via TT-SVD on H200 GPU. TT cores are amplitude-encoded on a 156-qubit QPU for hardware validation.
3. Results
Compression ratio 7,528× in 32.3 s; QPU fidelity 0.993647; quantum reservoir MSE 0.0048 vs. classical AR 0.0119.
4. API and Deployment
The pipeline is exposed via REST /decompose_voyage_tensor with auto-scaling to GPU for large tensors.
Complete Stage Inventory (Orchestration / Tensor / Quantum)
46-stage experimental campaign spanning orchestration compression, tensor analytics, and quantum algorithms.
Orchestration Stages
| # | Stage | Input | Output |
|---|---|---|---|
| 1 | Real-time fleet rerouting | TT-cores | MIP solver <1 min |
| 4 | Scenario simulation | TT-cores + disruption mask | Cost delta +3.69% |
| 7 | Cross-validation | 5 synthetic seeds | Ratio 7528× ± 0 |
| 8 | Transfer learning | Original cores + new cargo | Extended cores (31 cargoes) |
Tensor Stages
| # | Stage | Input | Output |
|---|---|---|---|
| 9 | Large-tensor TT decomposition | 15k×30×104×5 tensor | 7,528× compression, 32 s |
| 10 | Pareto frontier | Ranks 2–16 | Elbow at rank 5 |
| 11 | Anomaly detection | Rank-4 reconstruction | 4.84 M anomalies flagged |
| 22 | Forecast from G₂ | G₂ weekly slices | RMSE 0.0468 |
Quantum Stages
| # | Stage | Input | Output |
|---|---|---|---|
| 28 | MPS amplitude encoding | TT-cores → 3-qubit state | Fidelity 0.9936 |
| 29 | Quantum kernel matrix | 4 ports, ZZFeatureMap | 10 kernel entries |
| 30 | QAOA route sampling | 3-qubit Hamiltonian | Optimal route 30.9% |
| 36 | Quantum reservoir forecasting | G₂ time series | MSE 0.0048 |